
Practical steps aligned to people, process, technology, and data — so your analytics outcomes aren’t built on guesswork
Contents
- Real world measures to establish high quality data within your Data Ecosystem.
- A 3-phased implementation approach
- Final thought: Anchor everything to Business Impact
In my last article outlining how a mature, data driven culture breaks out into an effective data eco-system, I highlighted that data initiatives need to consider the whole eco system in order to ensure they are delivering measurable ROI.
Another factor that can undermine the benefits of a data initiative is the quality of the data being processed. So what real-world Data Quality Management (DQM) measures should be considered. To explore this lets again, look across the whole data eco-system:
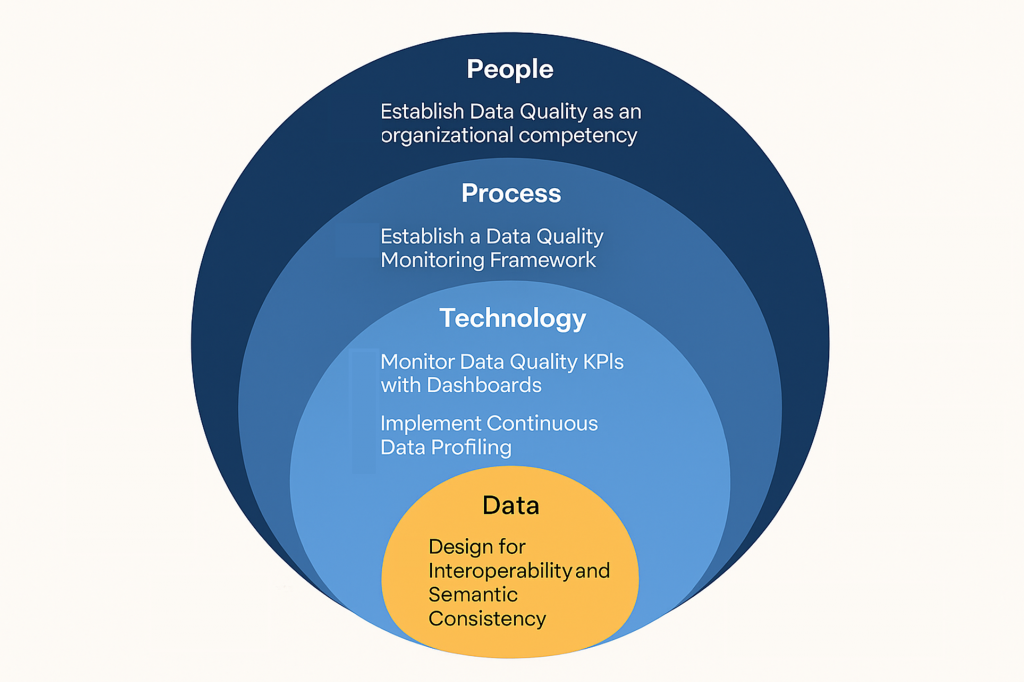
People
- Establishing Data Quality as an organisational competency
Organisations that are world-class at managing the quality of their data, look on this as an organisational competency that is technology enabled. Ownership of data must sit within the business with those who create it and use it in their day-to-day work. Managing the quality of this data is a key aspect of this ownership responsibility. I’ve often found that timing-wise, exploring how data quality can impact the outcome of a new data initiative, especially where there is a strategic imperative or significant business case at stake, opens up opportunities to explore with the business how they will measure and manage the quality of the associated data.
Other effective measures to consider can include embedding quality into data literacy and training programs and utilising effective change communications to celebrate teams that improve data quality and link it to business outcomes.
2. Appoint Data Stewards and Owners
At the risk of stating the obvious, it’s important to recognise that data quality management is an ongoing activity. Establishing responsibility within the business to monitor and maintain the quality of data is critical. Data stewards monitor quality, highlight issues and ensure they are resolved, while data owners make decisions about data use and remediation. These roles do not have to be fulltime.
The challenge here often is getting the business, (who are already busy taking care of business), to agree to pick up these extra tasks. Additional leverage from senior people within the organisation can help. I worked on a project for a large tobacco multi national where, through upsetting a senior manager by demonstrating the current poor quality of data and its impact upon their requirements, we generated sufficient “leverage” to get the business to agree to pick up ongoing DQM activities.
Process
3. Establish a Data Quality Monitoring Framework
It is important to ensure thoroughness and consistency in your approach to data quality management by defining clear data quality dimensions (accuracy, completeness, consistency, timeliness, validity, uniqueness) and aligning them with business KPIs and regulatory requirements.
If we have been successful in establishing the importance of data quality with business stakeholders then they should naturally appreciate the importance of establishing this capability and be willing to spend time working with you to define requirements. Furthermore, as you rollout analytics, the business are likely to see things they are not expecting and that they don’t like. Their first inclination will be to assume the data is wrong. Therefore having the ability to quickly confirm if this is the case or not may prove to be a pivotal factor in whether a new data or analytics tool is successful.
Aligning DQ to processes and analytical use cases is critically important. Organisations hold masses of data and it isn’t feasible to apply rigorous quality management to all of it. Attempting to boil the ocean is a phrase that is often used here. Instead focus on the entities and attributes that make the biggest difference to your process and analytical use cases. Measure and monitor them regularly. Again, in my experience the most sensible way in which to address this is to recognise it as a risk within your data initiatives and include sufficient resources to address it as part of your project or programme.
Technology
Once the data quality framework, processes and organisation have been established, technology can be utilised to automate monitoring, reporting and cleansing.
4. Maintain a Centralised Metadata and Lineage Repository
To establish, maintain and promote trust in the quality of data it is also important for consumers to have the ability to track where data comes from, how it changes, who uses it and for what purpose. A popular trend currently is for organisation to establish a product-based approach to data and analytics and the ability to establish trust in data is a fundamental acceptance criterion for data products.
Tools like Collibra, Alation, or Microsoft Purview help build trust and transparency across your data ecosystem.
In my previous role at Telefonica Tech we were big advocates of the Data Product approach and the adoption of Microsoft Purview by clients was steadily increasing. Microsoft are developing Purview as a toolset to support the management of data products.
5. Monitor Data Quality KPIs with Dashboards
In order to operationalise your data quality framework and to enable data stewardship and ownership you will need dashboards and KPIs to enable ongoing visibility and monitoring of data quality. These tools enable teams to visualise metrics like error rates, completeness scores, and SLA breaches. They also enable real-time alerts to trigger remediation workflows.
6. Implement Continuous Data Profiling
Once you have established your key data quality measures you can establish automated, ongoing checks for anomalies, duplicates, and missing values using tools like Informatica, Talend, or Ataccama. You can also automate data profiling as part of your ingestion pipelines into your data platform in order to catch issues early.
Telefonica Tech’s data platform framework has a data quality engine that enables automated profiling such as this. It also promotes extensions to curated data models with data quality dimensions to enable data consumers to decide whether to include or exclude questionable rows of data and to monitor the impact of data quality upon key metrics.
An agile approach to establishing this capability works well in my experience. As you learn more around the measures that are critical and problematic (i.e. require regular attention), you can iteratively refine your profiling. This is an ongoing activity that is never complete so make sure you factor in time and effort to maintain it.
7. Automate Data Cleansing and Enrichment
Technology can be used at the point of entry in order to standardise formats, correct errors, and enrich records with third-party data. You can also use reference data and master data management (MDM) tools to ensure consistency across systems, especially for key enterprise entities such as Customer, Supplier, Product, Service and Employee.
8. Leverage Machine Learning for Anomaly Detection
AI technologies offer an opportunity for more advanced automation. It is possible to train models to detect outliers, drift, or unexpected patterns in real time. This is especially useful in high-volume, high-velocity environments like IoT or financial services.
This technology can be used with great effect by Major Banks to detect credit card fraud. Machine Learning (ML) models flag outliers in transaction patterns in real time, triggering alerts to customers and customer services teams. It is also used in IoT sensor monitoring and predictive maintenance.
Data
9. Design for Interoperability and Semantic Consistency
It is all very well monitoring and remediating data quality issues after the event, but we can minimise the likelihood of data quality issues by ensuring that the data and IT teams are joined up and working together to ensure that high quality data is being designed and planned for at an enterprise architecture level. Mature data organisations use common data models, taxonomies, and ontologies to align meaning across systems. This is especially critical in federated or multi-cloud environments. Ensuring that projects are implementing the correct data entry controls and that we are striving for single, authoritative sources of data makes the data quality management task easier.
Putting these planning processes in place can be a significant undertaking so start by opening up lines of communication and collaboration between data and enterprise architects.
So how to get started with enterprise data quality management?
Reading through that long list of measures, it sounds like there is lots of work, time and investment to establish effective data quality management. However, as with all aspects of your data transformation journey, there is a practical and effective approach to getting started.
Building a data quality capability in parallel with your analytics investments is not just strategic, it’s essential. Here’s an example of a pragmatic, structured, three-phased approach to establish data quality practices within your data ecosystem, sequenced to align with real-world constraints like team bandwidth, budget, and data maturity.
Im including this as an illustrative example of an approach that might work for you however every organisation is different and as with every planning exercise its important to get the right people in the room to have the conversation and to agree on an approach that fits.
Phase 1: Start Small: Align to Analytics ROI
The initial goal is to establish credibility and prove early value in one or two analytics initiatives. The objective is to demonstrate that improved data quality leads to better model performance or faster insight delivery. Taking an agile approach makes sense as failing fast, learning and iterating will enable you to progress quickly
- Priority 1: Data Quality Framework. Define success for data quality in the context of a high-impact analytics project (e.g. customer churn model or sales forecasting). Use simple metrics like accuracy and completeness.
- Priority 2: Data Profiling & Quality Rules. Profile source data feeding the analytics model. Flag missing values, outliers, or inconsistencies. Embed simple rules in the pipeline (e.g. “Reject null customer segments”).
- Priority 3: Dashboards for Data Quality KPIs. Build a lightweight dashboard to visualise data quality KPIs over time (e.g. completeness, record count, % anomalies — specific to your analytics use case).
- Priority 4: Appoint Data Owners. Assign a data steward within the analytics project team. This person owns remediation decisions and becomes your internal champion.
Progress to the next phase, once you have established patterns that have proven to be effective across analytics streams and improve data transparency.
Phase 2: Scale and expand across projects with tooling
The objective now is to establish shared practices, reduce redundancy, and create a “data quality by default” mindset.
- Priority 5: Automated Cleansing and enrichment. Introduce standardisation scripts, use MDM for key domains like customer or product. Start enriching sparse fields with external data where needed.
- Priority 6: Metadata and Lineage repositories. Deploy tools like Microsoft Purview or open-source Amundsen. Begin tracking where your data comes from, how it’s transformed, and who uses it.
- Priority 7: Build a Data Quality community. Create a cross-functional working group (analytics leads, data engineers, stewards) that meets monthly to share lessons and align on standards.
Phase 3: Optimise. Embed Data Quality into the organisation’s culture.
Make high data quality sustainable and proactive at scale
- Priority 8: ML for Anomaly detection. Start with a pilot — e.g. flagging unexpected sales spikes or customer duplicates. Monitor precision and recall.
- Priority 9: Semantic Models and Interoperability. Align semantics across domains: e.g. make “customer” mean the same thing across CRM, ERP, and analytics systems. Use ontologies and business glossaries.
- Priority 10: Data Quality Culture. Make data quality part of training, onboarding, and team OKRs. Celebrate progress. Showcase wins tied to analytics success.
Final thought: Anchor everything to business impact.
The most important thing is to always remember when investing to build out your data quality capability, tie every data quality improvement to an analytics initiative that answers a strategic question or reduces risk. That’s how you keep momentum and funding. This is far from the only approach you can take but piggybacking on investments in data business cases is a good way to fund a capability that otherwise can be a tough sell.
It would be great to hear how this aligns with the efforts and initiatives within your own organisation. Are you adopting any of the measures outlined here or taking a different approach? How is it going? What successes and challenges are you experiencing.
If you’d like to discuss any of these topics or to explore how I can help, please get in touch.
In my next blog article, I will be speaking to an expert from one of my former client organisations to understand how they are managing the challenge of delivering high quality data in their own real-world, complex data eco system.
Leave a Reply